DirtyCred Remastered: how to turn an UAF into Privilege Escalation
Background
A few weeks ago, @kiks and I started to search for some recent CVEs in order to pratice our kernel exploitation skills.
We chose CVE-2022-2602 as our target for two reasons:
- There wasn’t a public exploit yet, only a PoC.
- It involves
io_uring, so it was a good way to learn more about it.
In the end, we were able to create a functional exploit using two different techniques: userfaultfd and inode locking. FUSE exploit coming soon, I’ll update this blog post :)
Go checking out @kiks’ blogpost about the same vulnerability here :)
I’ll start this blogpost by explaining some concepts that are useful in order to understand the vuln.
File Descriptors
Briefly, a file descriptor is just a number, used by processes in user-space to refer to open resources.
It could be a file, a UNIX socket, a network socket, an userfault handler, a message queue…ANYTHING!
Each process starts with three file descriptors:
stdin-> fd 0stdout-> fd 1stderr-> fd 2
They represent the three standard communication channels of a process. This number is used as an index in the open file table of the OS, which keeps track of all resources opened by processes on the system.
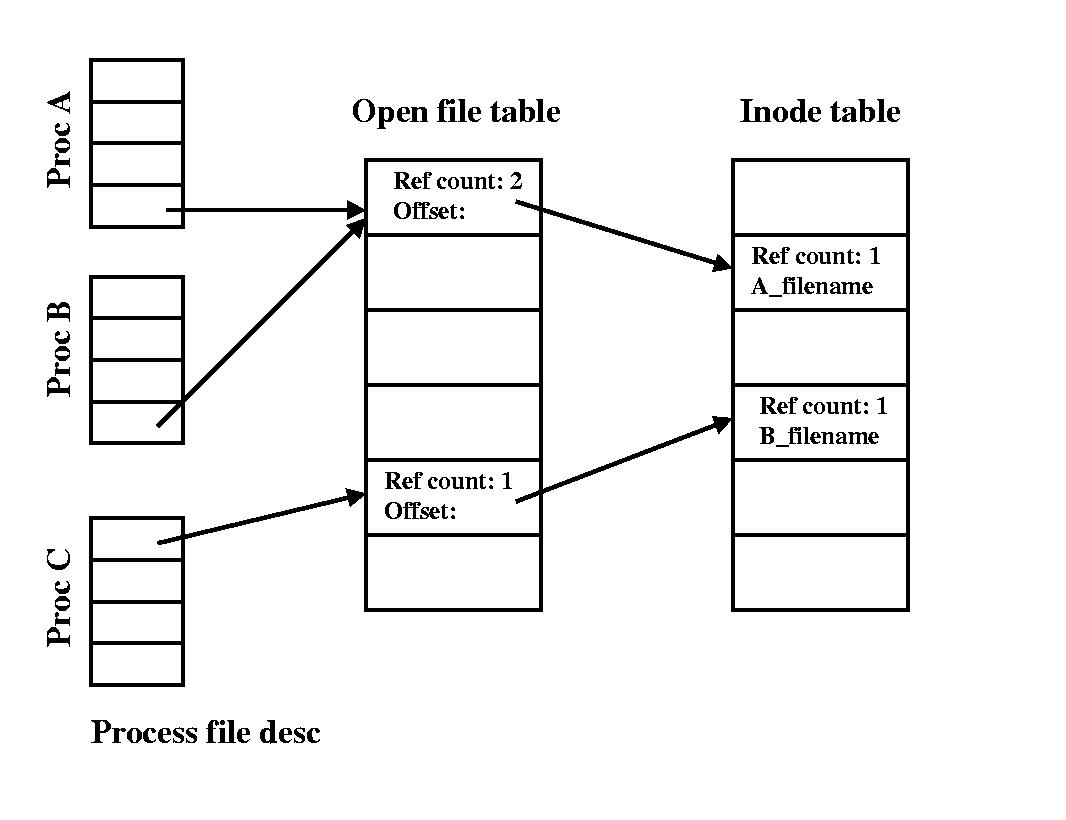
More info here
Reference Counting
Each file descriptor has a reference count number associated with it.
This is used by the OS to check when a file descriptor is no longer referenced and then the memory associated with it can be freed.
For example, a call to dup2() will increment the reference count of a file descriptor. Instead, a close() will decrement the reference count.
int main(int argc, char **argv){
printf("Right now I'm using fd 1 to print this out!");
dup2(1,99);
// Now stdout has two references
// Let's close fd 1 --> stdout's ref is decremented
close(1);
// Stdout is still alive because ref = 1
write(99, "Hello from fd 99!\n", 20);
exit(0);
}
Things can be more complicated if a file descriptor is sent from one process to another. I won’t go into details here, Google Project Zero has a great blogpost about the linux garbage collector, I consider it a must read :) It also explains how reference counting cycles are handled, which is important in order to understand the root cause of the vuln.
open: follow the white rabbit into the kernel
Let’s talk a little bit more about file fds.
What happens in the kernel when an open() system call is issued? Let’s take a look into kernel source code:
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)
{
if (force_o_largefile())
flags |= O_LARGEFILE;
return do_sys_open(AT_FDCWD, filename, flags, mode);
}
open indirectly calls do_sys_openat2:
static long do_sys_openat2(int dfd, const char __user *filename,
struct open_how *how)
{
struct open_flags op;
int fd = build_open_flags(how, &op);
struct filename *tmp;
if (fd)
return fd;
tmp = getname(filename);
if (IS_ERR(tmp))
return PTR_ERR(tmp);
fd = get_unused_fd_flags(how->flags);
if (fd >= 0) {
struct file *f = do_filp_open(dfd, tmp, &op);
if (IS_ERR(f)) {
put_unused_fd(fd);
fd = PTR_ERR(f);
} else {
fsnotify_open(f);
fd_install(fd, f);
}
}
putname(tmp);
return fd;
}
The do_filp_open function will call path_openat, which will eventually call kmem_cache_zalloc() to allocate an empty file:
static struct file *__alloc_file(int flags, const struct cred *cred)
{
struct file *f;
int error;
f = kmem_cache_zalloc(filp_cachep, GFP_KERNEL);
if (unlikely(!f))
return ERR_PTR(-ENOMEM);
f->f_cred = get_cred(cred);
error = security_file_alloc(f);
if (unlikely(error)) {
file_free_rcu(&f->f_u.fu_rcuhead);
return ERR_PTR(error);
}
atomic_long_set(&f->f_count, 1);
rwlock_init(&f->f_owner.lock);
spin_lock_init(&f->f_lock);
mutex_init(&f->f_pos_lock);
f->f_flags = flags;
f->f_mode = OPEN_FMODE(flags);
/* f->f_version: 0 */
return f;
}
struct file
kmem_cache_zalloc returns a struct file struct. This is the low-level representation of an opened file:
struct file {
union {
struct llist_node fu_llist;
struct rcu_head fu_rcuhead;
} f_u;
struct path f_path;
struct inode *f_inode; /* cached value */
const struct file_operations *f_op;
/*
* Protects f_ep, f_flags.
* Must not be taken from IRQ context.
*/
spinlock_t f_lock;
enum rw_hint f_write_hint;
atomic_long_t f_count;
unsigned int f_flags;
fmode_t f_mode;
struct mutex f_pos_lock;
loff_t f_pos;
struct fown_struct f_owner;
const struct cred *f_cred;
struct file_ra_state f_ra;
u64 f_version;
#ifdef CONFIG_SECURITY
void *f_security;
#endif
/* needed for tty driver, and maybe others */
void *private_data;
#ifdef CONFIG_EPOLL
/* Used by fs/eventpoll.c to link all the hooks to this file */
struct hlist_head *f_ep;
#endif /* #ifdef CONFIG_EPOLL */
struct address_space *f_mapping;
errseq_t f_wb_err;
errseq_t f_sb_err; /* for syncfs */
} __randomize_layout
__attribute__((aligned(4))); /* lest something weird decides that 2 is OK */
This struct is allocated in a so-called cache, in this case the filp cache.
In case you don’t know what the hell I’m talking about, don’t worry, I got you covered. This video explains in great details the kernel memory allocator. If you speak Italian, I suggest you watching these videos about kernel memory allocator.
io_uring
io_uring is a linux subsystem for asynchronus I/O.
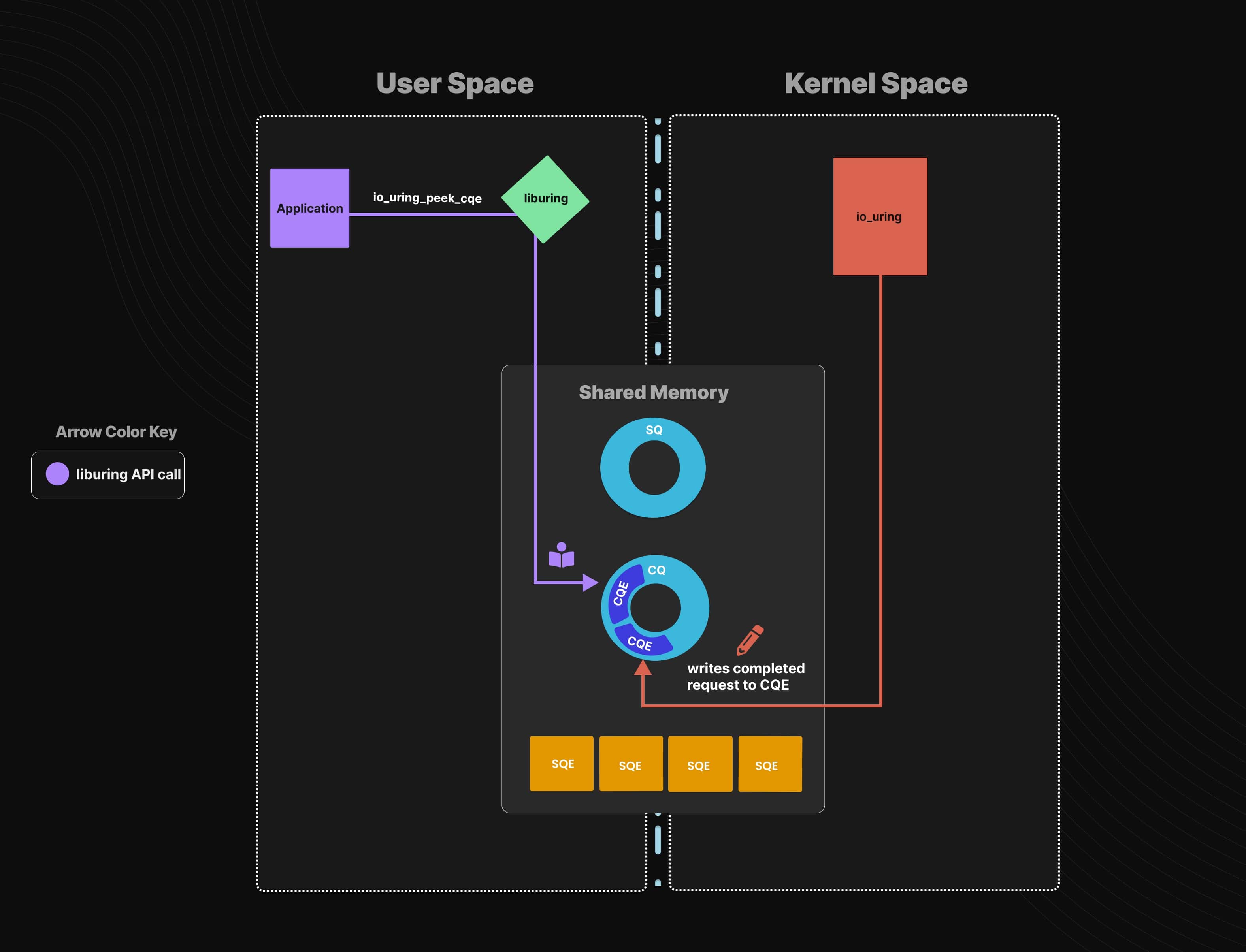
If you want to know more about IO_URING, I recommend you reading
@chompie’s blogpost.
Root Cause Analysis
The first thing we did, was to try the public PoC available, on a vulnerable kernel with KASAN enabled.
[ 35.652903] ==================================================================
[ 35.655540] BUG: KASAN: use-after-free in __io_queue_sqe+0x20f/0x4d0
[ 35.655540] Read of size 8 at addr ffff8880086c8528 by task iou-sqp-147/149
KASAN report confirms that we are dealing with an use-after-free vulnerability in the io_uring subsystem.
[ 35.655540] The buggy address belongs to the object at ffff8880086c8500
[ 35.655540] which belongs to the cache filp of size 232
[ 35.655540] The buggy address is located 40 bytes inside of
[ 35.655540] 232-byte region [ffff8880086c8500, ffff8880086c85e8)
[ 35.655540] The buggy address belongs to the page:
[ 35.655540] page:(____ptrval____) refcount:1 mapcount:0 mapping:0000000000000000 index:0x0 pfn:0x86c8
[ 35.655540] flags: 0xfffffc0000200(slab|node=0|zone=1|lastcpupid=0x1fffff)
[ 35.655540] raw: 000fffffc0000200 0000000000000000 dead000000000122 ffff888005614b40
[ 35.655540] raw: 0000000000000000 00000000800c000c 00000001ffffffff 0000000000000000
[ 35.655540] page dumped because: kasan: bad access detected
It gives us also information about the address: it’s inside the filp cache, so it involves file descriptors.
After analyzing the public PoC, we understood the root cause of the vulnerability:
The problem arises when a kernel thread, that is completing an OP_WRITEV request in io_uring using a registered file, is somehow paused,
while that file is being freed in userland.
This is achieved by exploiting the behaviour of the unix_gc garbage collector, which will search for all socket buffers that are inside an unbreakable cycle and it kfree()s them.
By inserting io_uring file descriptor inside an unbreakable cycle, it’s possible to trigger the kfree() on it.
There are different ways to pause a kernel thread, in the following sections I’ll describe some of them.
Exploitation plan - userfaultfd
One possibility is using userfaultfd, by issuing an OP_WRITEV request with an iovec that is allocated in zero-demand paging.
In this situation, the first access to this chunk of memory will cause a page fault.
But, in the io_uring context, when the page fault is triggered? Let’s see the implementation of the io_write, which is the OP_WRITEV function handler:
static int io_write(struct io_kiocb *req, unsigned int issue_flags)
{
struct iovec inline_vecs[UIO_FASTIOV], *iovec = inline_vecs;
struct kiocb *kiocb = &req->rw.kiocb;
struct iov_iter __iter, *iter = &__iter;
struct io_async_rw *rw = req->async_data;
bool force_nonblock = issue_flags & IO_URING_F_NONBLOCK;
struct iov_iter_state __state, *state;
ssize_t ret, ret2;
[Truncated]
ret = io_import_iovec(WRITE, req, &iovec, iter, !force_nonblock); //It will trigger the page fault
[Truncated]
}
io_import_iovec will indirectly call copy_from_user(), which will import the iovec from user-space.
If the iovec is allocated with zero-demand paging, the copy_from_user() will trigger the page fault: the kernel thread that is completing
the write request will be blocked during the copy_from_user(), waiting for userland to finish the page fault handling.
In userland, the page fault handler can free the registered file by invoking the unix_gc garbage collector, which will free the io_uring’s file
descriptor and this will also trigger the kfree() of the struct file belonging to the file we are writing to.
When the kernel thread resumes its execution, it will write the content of the iovec
inside a file, described by a freed struct file.
If we manage to replace the freed struct file with another one, the io_write will write the content to the replaced file.
Turning it into privilege escalation
Since the goal is to achieve privilege escalation, the first thing I thought was to replace the file with /etc/passwd, in order to write a new entry inside it.
Yes, it’s possible to write inside /etc/passwd, because the read/write check is performed before the page fault handler is triggered!
If we open a file in O_RDWR mode and then substitute it with /etc/passwd, it’s possible to write a new entry inside the passwd file.
So the exploit workflow is:
- Open an
io_uringfile descriptor. - Add a registered file to it.
- Insert
io_uringfd inside an unbreakable cycle. - Issue an
io_writerequest, which will be paused using the page fault handler. - Trigger the
kfree()of thestruct fileof the registered file (triggeringunix_gcgarbage collector). - Replace the freed file with
/etc/passwd. - Resume write operation.
- Root!
This is what happens inside the filp cache:
- Allocation of a
struct filefor a readable/writeable file:

- Triggering the free of the
struct file:

- Replacing the freed
struct filewith/etc/passwd:

If we win the race condition, the content of the iovec is written inside /etc/passwd.
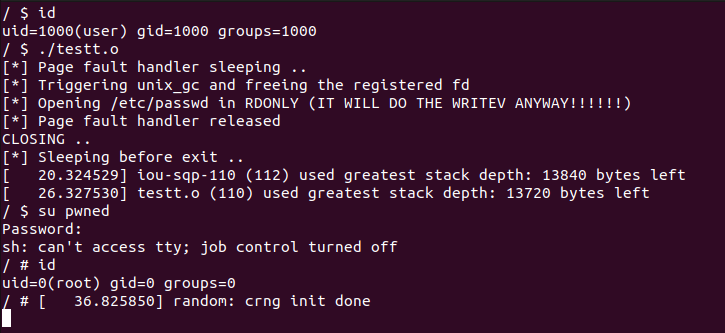
PoC, or it didn’t happen
The PoC adds a new entry inside /etc/passwd for a new root user called pwned with password lol.
Exploitation plan - inode locking
Sadly, userfaultfd is not allowed anymore for unprivileged users on almost all linux distributions; so it won’t work :(
Fortunately, there are other techniques that allows to pause a kernel thread. One of these is exploiting the inode locking mechanism.
What is inode locking?
Inode locking is a mechanism used by filesystems, in our case the ext4 filesystem, to ensure that only one process at the time can write to a file.
This is done inside the write implementation of the filesystem:
static ssize_t ext4_buffered_write_iter(struct kiocb *iocb, struct iov_iter *from){
ssize_t ret;
struct inode *inode = file_inode(iocb->ki_filp);
inode_lock(inode);
[Truncated]
ret = generic_perform_write(iocb->ki_filp, from, iocb->ki_pos);
[Truncated]
inode_unlock(inode);
return ret;
}
Before performing the write operation, the kernel thread tries to grab the lock on the inode.
More info here
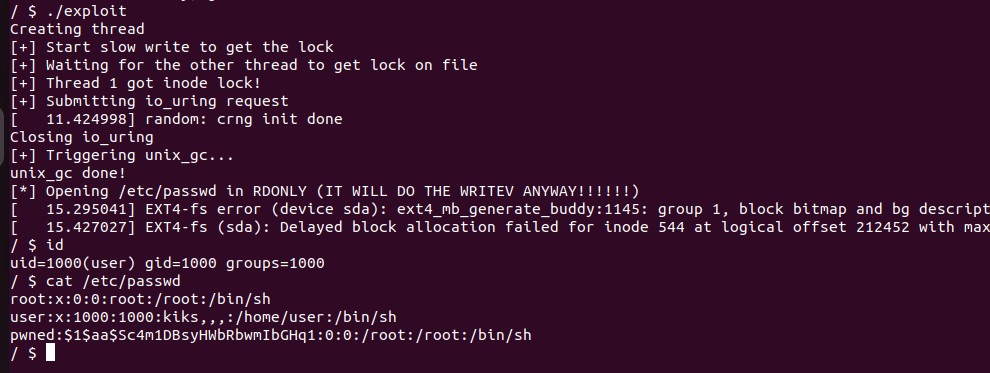
It is possible to exploit that by creating another thread that keeps writing to the target file, and then issuing the OP_WRITEV request.
In this situation, the kernel thread that is performing the OP_WRITEV request is blocked until the other thread has completed the write operation.
We can use this mechanism as a replacement for the userfaultfd technique. The rest of the exploit doesn’t change.
PoC, or it didn’t happen pt. 2
Exploitation plan - FUSE filesystem
COMING SOON…
Conclusion
I had a lot of fun understanding how to exploit this vuln, and I learned a lot about linux internals :)
Huge thanks to @kiks. I had a lot of fun working with him on this project, he is a very skilled guy :)
Check out his blogpost on the same vulnerability: it goes in much more details on issues we had during the exploit developement phase, he also introduces the new KRWX feature we used during exploit developement.
I’ve uploaded the POCs here